Transformer-based large language models have taken the world by storm in recent years, and achieved impressive capabilities in solving general reasoning problems.[3] That being said, LLMs are still quite limited in scope, as they are very centred around textual interaction. Recently I have become interested in the underlying mechanics of transformer models, and how they relate to past attempts at machine reasoning, such as rule engines.[2] In this article I will discuss some of these relationships, and how I hope to use this knowledge to build transformer models with broader reasoning capabilities that extend beyond the realm of text, and could create AI systems capable of solving complex reasoning problems in real time in a constantly changing world.
I made a rule engine that plays Minicraft, you can find it on GitHub.
Rule Engines
Reasoning is the process of taking a bunch of facts about the world, using those to infer more facts which can in turn be used to infer more facts until you manage to deduce some information of value. My favourite mental model for thinking about machine reasoning is rule engines, also known as production systems or expert systems, which were a popular type of AI system in the 1980s. These systems consist of a knowledge base, which is a large set of simple declarative facts, and a set of rules, which define how new facts can be inferred.[2] These rules each have a list of preconditions, and when there are facts in the knowledge base that meet those conditions the rule fires and outputs one or more new facts based on the input facts. For example, if the knowledge base contains the fact “Billy is a bird” and the rule “If X is a Bird then X has feathers”, the rule will fire and produce the fact “Billy has feathers” which is then added to the knowledge base, possibly triggering more rules.
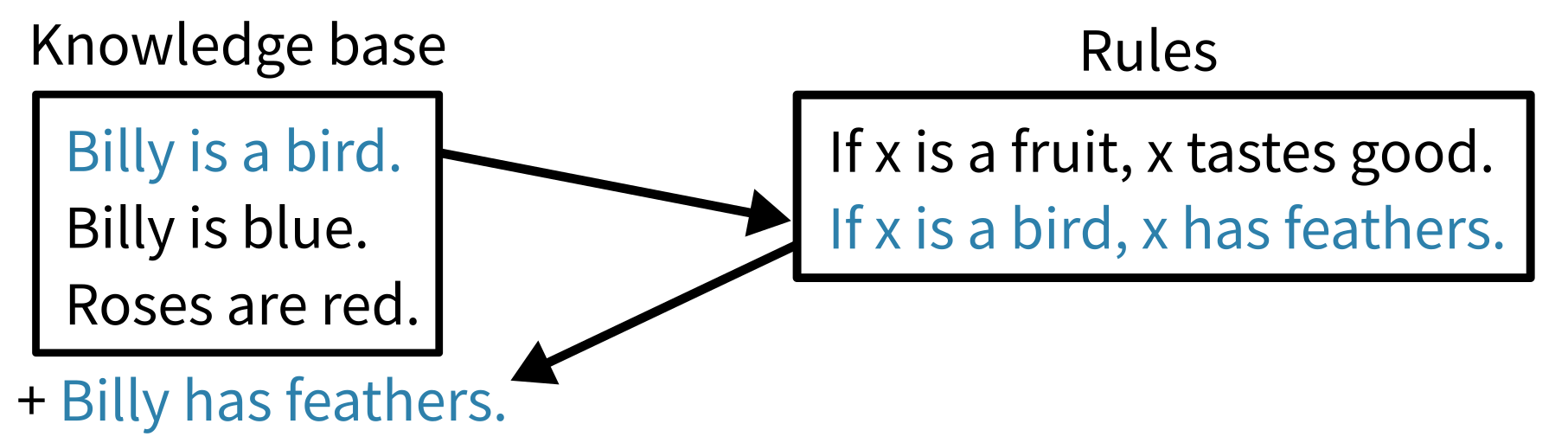
Rule engines are a nice way to think about reasoning because they separate the AI system’s knowledge from the reasoning process, and break both down into bite sized pieces. They also separate the definition of which inferences are possible and accurate from the process of deciding which inferences are worth making; just because a rule could be fired, doesn’t mean the information it produces will be useful! Rule engines have been largely overshadowed by machine learning (especially deep learning) in modern AI, and I personally don’t expect them to pave the way to our AI-powered future, but I still like to use them as an analogy for thinking about the structure and capabilities of modern systems.
Reinforcement Learning as Reasoning
When we think of human-level artificial intelligence, we usually think of a system that can make complex decisions about the world around it in real time. This area of artificial intelligence is called reinforcement learning, and I’ve discussed it in more depth in my previous article. Reinforcement learning is generally good at making relatively simple decisions quickly in response to dynamic stimuli, but solving complex reasoning problems in constantly changing environments is still an open problem.
Let’s think about how the rule engine-style reasoning from earlier might apply to reinforcement learning. As the agent receives new data from the environment, such as the pixel colours in a video feed, these can be added as facts to the engine’s knowledge base. Certain patterns present in these pixels might trigger rules which then emit facts representing higher-level observations, such as a group of yellow pixels probably being a coin. These observation facts might then trigger more rules that emit facts representing recommended actions, which are detected by an action subsystem and cause the agent to take action in the environment. We can also imagine past environment states represented in the knowledge base being used to predict future states, allowing more complex planning. Ideally there would be rules that allow both short and long term predictions, to allow planning at various levels of detail as discussed in my previous article.
The main problem with such a setup is how the rules would be acquired. Ideally we want them to be learned from interaction with the environment, otherwise the agent would have to be hardcoded for a specific task. This naturally raises numerous questions: How are these rules represented in a learnable way? What algorithm would be used to learn these rules, considering that a long chain of rules might exist between input data and outputs? To answer these questions, I propose we turn to transformer neural networks, the basis of large language models.
Transformer Models for Reasoning
Recently large language models (LLMs) have been taking the world by storm, which take a sequence of words as input and repeatedly predict appropriate next words in the sequence. The largest of these models have proven somewhat effective at reasoning problems, as they have seen examples of reasoning problems being solved in writing in their massive training datasets.[3] This seems like a fairly sensible way to approach reasoning, as it allows the model to tackle problems by learning step-by-step problem-solving methods from human examples. Also note that this mirrors the rule engine model of reasoning; the sentences provided to and generated by the LLM are like the facts in a rule engine, and the sequential generation of intermediate steps by the model mirrors the rule firings of a rule engine working towards a solution.
![]()
Something important to note about modern LLMs is that while they operate on sequences, the underlying model is not heavily reliant on the sequential structure of the data. This is because most LLMs use a type of neural network called a transformer, which is able to look up past elements in the sequence based on their content alone, regardless of where they are.[4] This heightens the analogy to rule engines, whose rules match against facts based on their content alone. Also, while most current LLM reasoning is based on text, the underlying transformer model is capable of being applied to pretty much any domain, such as video[1] and sound.[5] That said, most work on LLM reasoning is based on learning sequential reasoning methods from human writing, so it is more challenging to generalise state-of-the-art reasoning to other domains. This also suggests that these systems will struggle to surpass human reasoning capabilities, or learn more specialised algorithms for complex domains such as reinforcement learning.
Conclusion
Transformer models seem like a promising avenue for general purpose machine reasoning, given their present success in large language models, and their theoretical similarity to rule engines. By thinking of transformers as neural rule engines, I hope to amplify their reasoning capabilities and apply them to more complex problem scenarios like reinforcement learning.
References
[1] Brooks, Tim, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. “Video generation models as world simulators.” OpenAI (2024). https://openai.com/research/video-generation-models-as-world-simulators
[2] Forgy, Charles L. “OPS5 User’s Manual.” DTIC (1981). https://apps.dtic.mil/sti/citations/tr/ADA106558
[3] Helwe, Chadi, Chloe Clavel, and Fabian M. Suchanek. “Reasoning with Transformer-based Models: Deep Learning, but Shallow Reasoning.” 3rd Conference on Automated Knowledge Base Construction (2021). https://openreview.net/forum?id=Ozp1WrgtF5_
[4] Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser and Illia Polosukhin. “Attention is All you Need” Advances in Neural Information Processing Systems 30 (2017). https://papers.nips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
[5] Zhang, Yixiao, Baihua Li, Hui Fang, and Qinggang Meng. “Spectrogram Transformers for Audio Classification.” 2022 IEEE International Conference on Imaging Systems and Techniques (IST), June 21, 2022. https://doi.org/10.1109/ist55454.2022.9827729