Reinforcement learning is the subfield of machine learning that considers agents that learn behaviours through interaction with their environment. These systems have shown impressive capabilities for various tasks such as playing Atari games[5] and Go,[7] however they tend to be bad at other tasks that require more complex long-term planning.[2] Recently I’ve been researching state of the art techniques to overcome these issues and apply reinforcement learning to more complex challenges. This article will give a brief overview of key advances in reinforcement learning, and some recent work demonstrating how they could be used to enable more sophisticated planning in reinforcement learning systems.
Reinforcement Learning
Reinforcement learning considers AI agents which take actions within an environment in order to earn rewards over time. This generally works by training a neural network that takes the current environment state (e.g. the pixels on a game screen) as input and outputs the reward that the agent expects to receive in the near future for each action it could take. The agent will then choose the action it expects to yield the highest reward, and by doing this repeatedly the agent should naturally move towards its goals and avoid hazards.
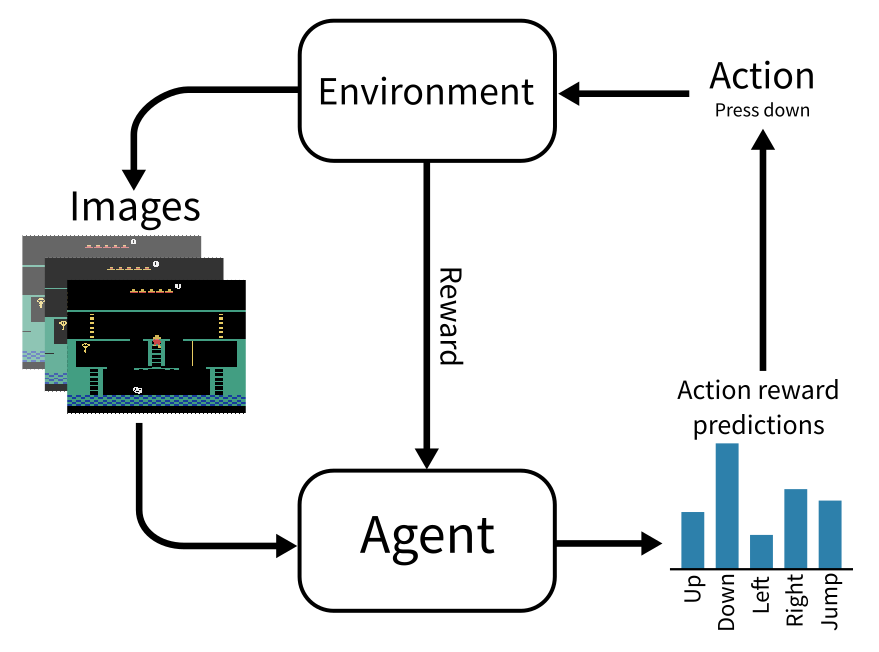
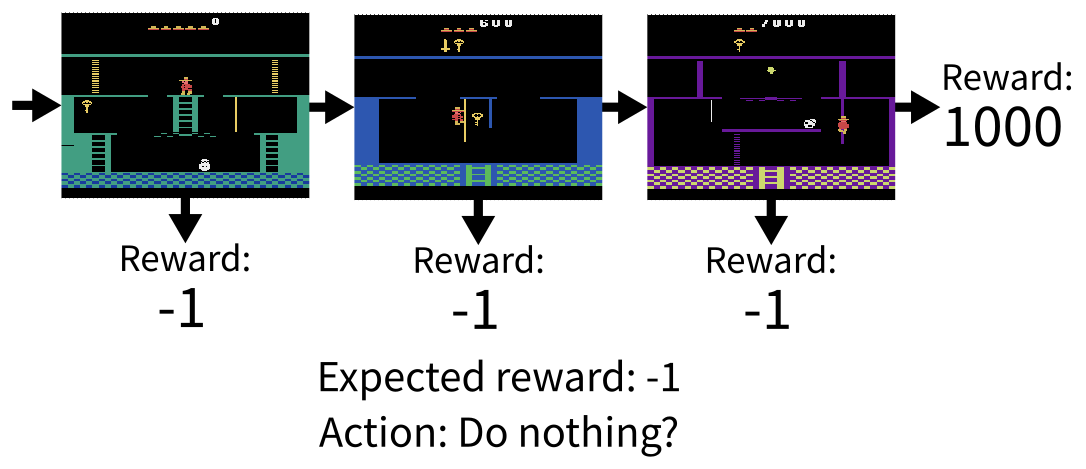
The main thing to note about reinforcement learning is that it is entirely focussed on gaining rewards. It doesn’t learn how actions affect the environment, or how they cause the agent to move, or how the environment naturally changes over time, it only cares about the relationship between actions and future rewards. This is fine if the agent is regularly receiving rewards or punishments, as it is fairly easy to correlate recent actions to the rewards they caused, however if the agent only receives reward feedback very occasionally, it might not learn anything at all! Suppose the agent is in a game where it needs to solve some puzzles to unlock the door to a treasure room, where it will find a vast trove of large rewards. As the agent does not receive any rewards until it works out how to enter the room, all it can learn is that any action it takes leads to no reward, so it will never be able to learn how to get to the rewards in the first place. This is a major problem with traditional reinforcement learning, which usually limits reinforcement learning to simple tasks with constant reward feedback for the agent to learn from.
Goal-Conditioned Reinforcement Learning
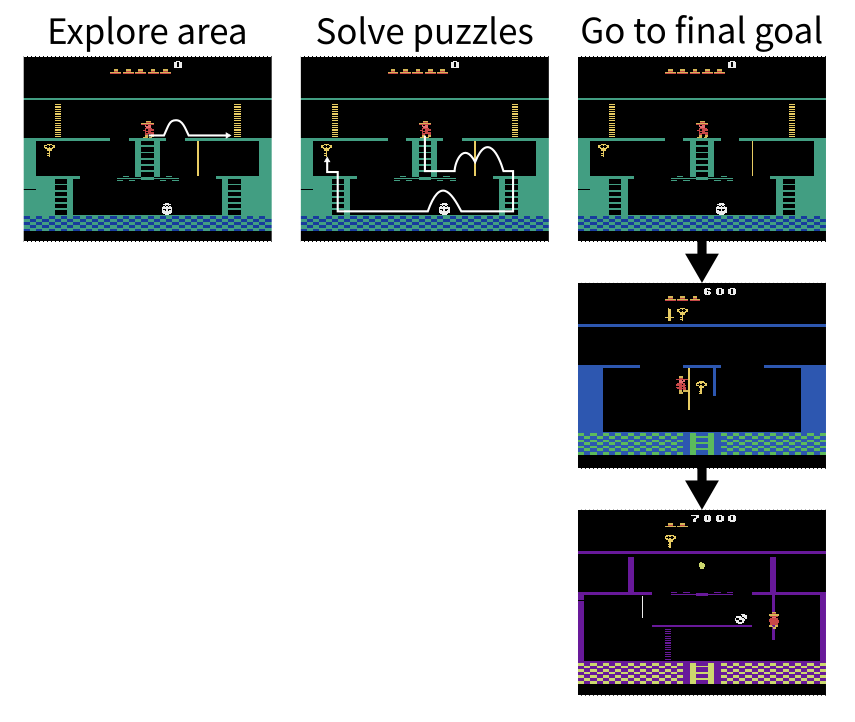
Instead of focusing solely on the rewards the agent receives from the environment, it can be more useful for the agent to learn how it can traverse between states in the environment, regardless of the reward it receives from them. One example of this is goal-conditioned reinforcement learning, where the agent learns a policy model that can select actions to achieve a given goal from the current state.[4] The goal can be chosen by the agent and updated as it progresses through the environment, such that it does not depend on the reward received by the agent. At first the agent will need to explore the environment by choosing goals that are reachable while pushing the boundaries of what it has seen before. Once the agent has learned enough about the environment it inhabits, it will have come across some high reward states and will be able to set those as goals in order to maximise reward. In the treasure room example from before, the agent might start by setting goals to walk around the nearby area to understand how the controls work, then it would set novel puzzle configurations as goals in order to search for possible solutions, then once it had reached the treasure room at least once it could set that as the goal so it can go straight to the high reward in the future.
At a technical level, a traditional reward-oriented reinforcement learning agent can be turned into a goal-conditioned agent by giving it an internal reward function based on whether or not the current goal is achieved.[4] This will naturally lead the agent to choose actions that will lead it towards the current goal, maximising this internal reward. Even if the agent fails to achieve its own goals, it can still learn by retroactively setting past goals to states that were actually reached, to learn how to reach those states again in the future. This technique is known as Hindsight Experience Replay and is a very important technique for goal-conditioned reinforcement learning.[1]
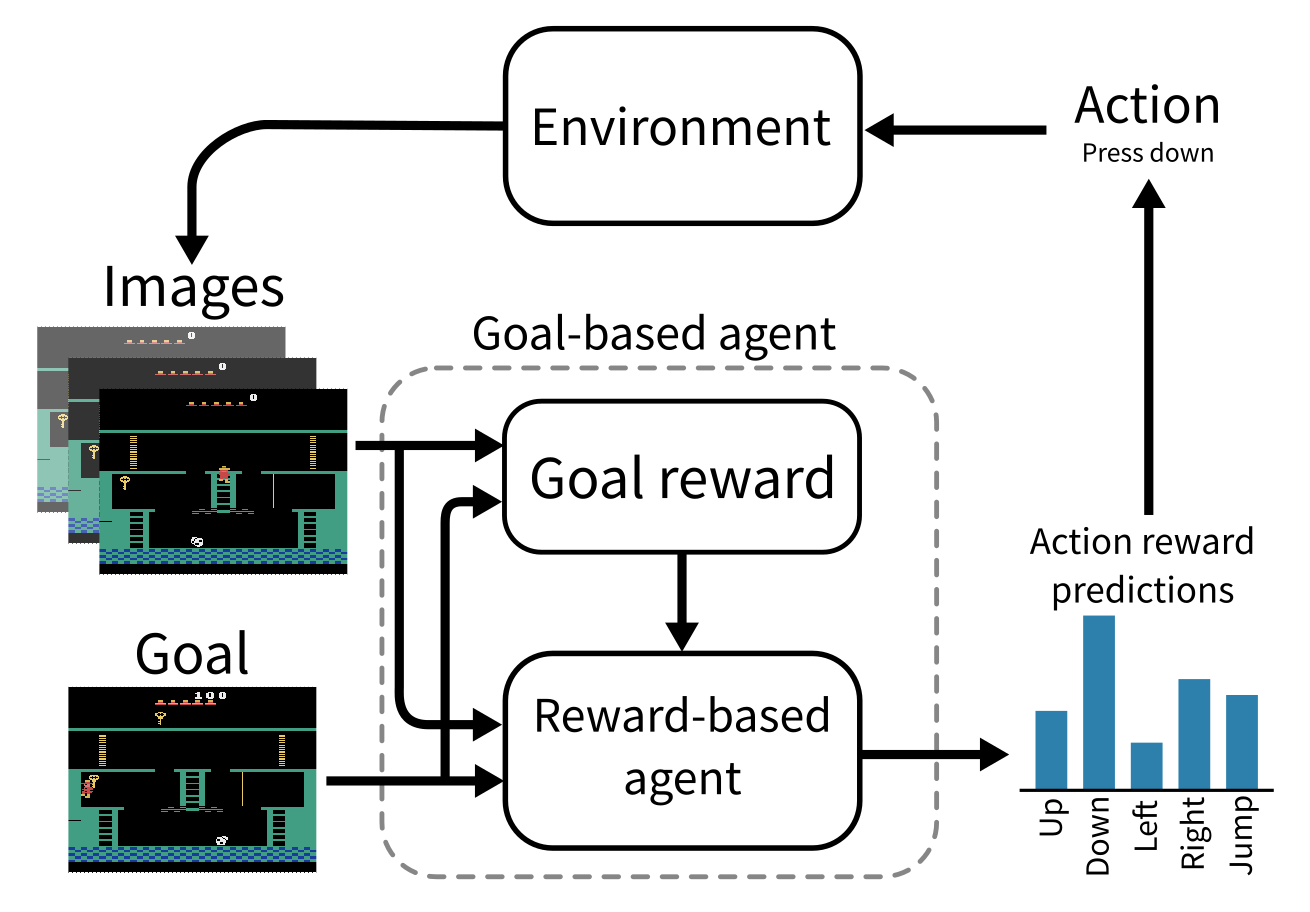
Goal-conditioned reinforcement learning is powerful because it separates the low level, reactive nature of the underlying reinforcement learning agent from high level goal selection. This allows the agent to respond to unpredictable short-term environment dynamics while maintaining a stable long-term plan.
Planning for Reinforcement Learning
In theory a goal-conditioned reinforcement learning agent could learn to work towards goals that are very far from its current state, however this is likely to be much harder than just learning how to get between states that are close to each other. After all, much of this knowledge should be transitive; if the agent knows how to get from A to B and from B to C, it should also know how to get from A to C without any further learning. This raises the need for compositional planning that allows the agent to break down complex goals into sequences of simpler ones that are easier for the underlying reinforcement learning agent to follow.
This idea is starting to sound a lot like traditional graph search problems, where an agent needs to find a path between two nodes following a sequence of connected edges. The dynamics of a reinforcement learning environment are usually much more complex than a nice simple graph, but many of the same principles can still apply. We can imagine the states of the environment to be the nodes of the graph, with edges representing pairs of states that can be easily reached from each other. More accurately, the edges might be annotated with a reachability score indicating how easy it is to get from one state to another. If the agent could learn this reachability score for pairs of states, it could plan sequences of states that are pairwise reachable to get from its current state to the goal, perhaps using graph algorithms to search over various possible routes.
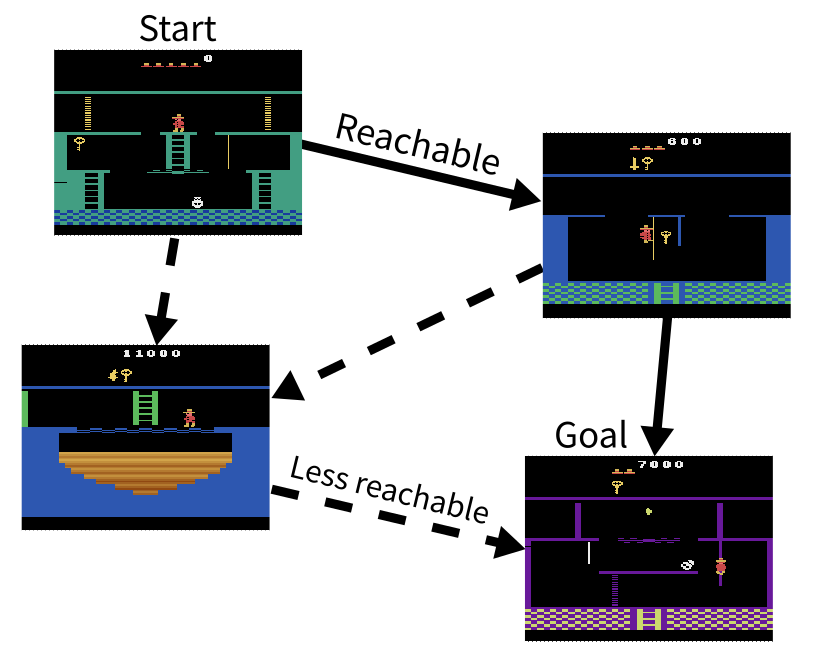
It just so happens that we already have a reachability score between pairs of states! Recall that the goal-conditioned reinforcement learning agents discussed earlier work by learning a reward function that is based on whether the agent expects to reach the current goal by taking a certain action from the current state. For a given current state and goal state, if there is an action with high expected reward that suggests the goal is reachable from that state, whereas if no action has high expected reward that means the goal is not easily reached. We can set any pair of states as the current and goal states to check their reachability from each other. Nasiriany et al.[6] use this trick to generate intermediate steps between the agent’s current state and the final goal, allowing the agent to master tasks much more quickly.
This technique works by selecting a final goal, then generating a random sequence of states in between those two goals, then using optimization techniques similar to those used to train neural networks to nudge those random states towards ones that actually form a realistic path between the start state and the goal state. This is a slow process, so it would be nice to have a model that could spit out a possible between state in a single pass. Also, it would be nice if the model could generate novel reachable states without a final goal in mind, allowing the agent to explore by rolling out its state graph into new areas of the environment. Ideally the agent could mix these two modes, making rough trajectories far into the future and then filling in the details later. Similar ideas have been explored in the field of long-form video generation, with the goal of planning out the long term plot of a video before filling all the individual frames.[3]
Conclusion
The techniques discussed in this article lay out a future research direction for AI agents that can plan far into the future while reacting dynamically to their changing environment. It is interesting to see how general planning and reasoning techniques might be applicable to reinforcement learning, and how advancements in these related fields could learn from each other. Following on from this, I’m hoping to research the latest techniques in ML reasoning to see how they could be applied to reinforcement learning and other domains.
References
[1] Andrychowicz, Marcin, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, Pieter Abbeel, and Wojciech Zaremba. “Hindsight experience replay.” Advances in neural information processing systems 30 (2017). https://papers.nips.cc/paper_files/paper/2017/hash/453fadbd8a1a3af50a9df4df899537b5-Abstract.html
[2] Ecoffet, Adrien, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, and Jeff Clune. “Go-explore: a new approach for hard-exploration problems.” arXiv preprint arXiv:1901.10995 (2019). https://arxiv.org/abs/1901.10995.
[3] Harvey, William, Saeid Naderiparizi, Vaden Masrani, Christian Weilbach, and Frank Wood. “Flexible diffusion modeling of long videos.” Advances in Neural Information Processing Systems 35 (2022): 27953-27965. https://papers.nips.cc/paper_files/paper/2022/hash/b2fe1ee8d936ac08dd26f2ff58986c8f-Abstract-Conference.html
[4] Liu, Minghuan, Menghui Zhu, and Weinan Zhang. “Goal-Conditioned Reinforcement Learning: Problems and Solutions.” Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, July 29, 2022. https://doi.org/10.24963/ijcai.2022/770.
[5] Mnih, Volodymyr, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, et al. “Human-Level Control through Deep Reinforcement Learning.” Nature 518, no. 7540 (2015): 529–33. https://doi.org/10.1038/nature14236.
[6] Nasiriany, Soroush, Vitchyr Pong, Steven Lin, and Sergey Levine. “Planning with goal-conditioned policies.” Advances in Neural Information Processing Systems 32 (2019). https://papers.nips.cc/paper_files/paper/2019/hash/c8cc6e90ccbff44c9cee23611711cdc4-Abstract.html
[7] Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, et al. “Mastering the Game of Go with Deep Neural Networks and Tree Search.” Nature 529, no. 7587 (2016): 484–89. https://doi.org/10.1038/nature16961.