Convolutional autoencoders are a widely used network architecture for distilling the underlying structure of an input image into a smaller vector representation. One notable shortcoming of convolutional neural networks is their poor ability to extract positional information from images [3], which is problematic for autoencoders that may want to use the positions of elements within an image for reconstruction or other tasks. One approach proposed to overcome this problem is CoordConv [3], which adds two extra channels to the input image containing the x and y positions of all pixels. This article investigates the application of CoordConv layers to autoencoders trained on randomly positioned handwritten digits from the MNIST dataset [2], demonstrating that autoencoders that include CoordConv layers are better able to extract positional information from these images than those that don’t.
The source code for this article can be found on GitHub.
Background
Autoencoders
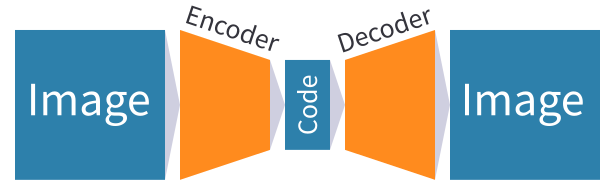
An autoencoder consists of two neural networks:
- An encoder, which takes an image as input, and outputs a (much smaller) vector embedding representing the image.
- A decoder, which takes the aforementioned vector embedding as input and outputs the original image that was passed to the encoder to produce that embedding.
The encoder and decoder are trained together by using images from the dataset as both the input data and target outputs. This setup aims to make the encoder learn to output vector embeddings that contain the underlying information necessary for the decoder to reconstruct the input images as accurately as possible.
CoordConv
When working with images, it is often useful to extract the locations of objects within an image. This might seem like a simple task for modern deep learning systems, however the convolutional architectures widely used for image processing are notoriously bad at extracting positional information [3]. One simple method to overcome this shortcoming is to explicitly provide positional information in the input image, by adding two extra channels to the input containing the x and y coordinates of each pixel. This approach was presented by Liu et al.[3], who call the network layer that adds these channels a CoordConv layer. This article focuses on comparing autoencoder architectures that include CoordConv layers with those that don’t.
It is also worth noting that network architectures using CoordConv layers typically replace the dense layer usually found at the end of a convolutional network with a global pooling layer, such as global max pooling. This is because a dense layer would learn different weights for different areas of the image, even though extracting positional information should behave the same for all parts of the image. This can cause issues if some parts of the image are not covered by the training set, whereas global pooling treats every part of the image the same so covering all possible locations during training is less important.
Randomly Positioned MNIST Dataset

The MNIST dataset [2] is a set of 70,000 images of handwritten digits between 0 and 9, widely used for testing computer vision systems. The digits in this dataset are centered within each image, so extracting positional information isn’t usually of great importance when working with this dataset. Instead the experiments in this article add positional information to the MNIST images by shrinking them down and randomly positioning them on a blank background. This means that in order to reconstruct these images, an autoencoder must somehow encode the position of a digit within the larger image.
Linear Probing
As well as simply seeing whether adding CoordConv layers allows an autoencoder to more accurately reconstruct input images, this article also analyzes how explicitly the learned embeddings encode the position of digits within images. The position might be concisely represented by a small subset of the vector elements, or it might be implied by a complex combination of all the elements. One way to analyze the information stored in black-box vector embeddings is linear probing [1], whereby a supervised linear model is trained that takes the vector embeddings as input and outputs the information expected to be encoded in the vector, in this case the digit positions. The idea here is that if the embeddings explicitly represent the digit positions, then training an accurate linear model on the embeddings should be fairly easy. On the other hand, if the embeddings merely imply the positions through some complex combination of features, training a simple linear model will be much harder. By comparing the accuracy of linear models trained on embeddings from autoencoders that do and don’t use CoordConv layers, we should be able to better understand the content of the embedding vectors produced by each model.
Experimental Setup
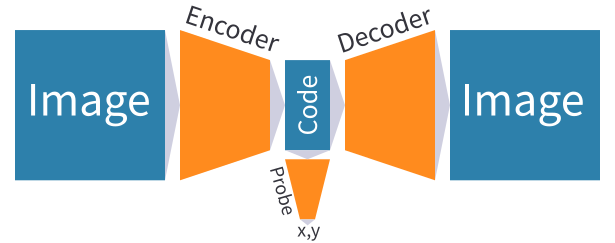
The setup for the experiments discussed in this article consists of three different neural networks:
- The encoder, which takes 64x64 grayscale images from the randomly positioned MNIST dataset as input, and outputs vector embeddings of length 50.
- The decoder, which takes 50-element vector embeddings as input and outputs 64x64 grayscale images.
- The probe, which takes 50-element vector embeddings as input and outputs predicted digit positions, which are vectors of size 2.
Two versions of this setup are used: one in which the encoder and decoder both contain CoordConv layers, and one in which neither of them do. The probe is always a single-layer linear model. The exact network architectures can be found in the GitHub repository.
The encoder and decoder are trained together, using images from the randomly positioned MNIST dataset as both the input and target output, with the output of the encoder fed directly into the decoder. The probe is trained by itself using embeddings produced by the already trained encoder as input, and the digit centers as the target output.
Results

The above figure shows a comparison of the reconstructed images produced by the two versions of the autoencoder, and the digit positions predicted by the linear probe based on the embedding vectors. The reconstructed images produced by both autoencoders look very similar to the original images, however the predicted positions are much more accurate for the CoordConv autoencoder. This suggests that adding CoordConv layers to the autoencoder has allowed it to more explicitly encode the digit positions.
Conclusion
These experiments suggest that adding CordConv layers to convolutional autoencoders improves their ability to encode positional information present in input images. This is useful not just for enhancing autoencoders, but also for extracting positional information in an unsupervised manner that can be used for other tasks, such as detecting the locations of cars on a road.
The source code for this article can be found on GitHub.
References
[1] Alain, Guillaume, and Yoshua Bengio. “Understanding Intermediate Layers Using Linear Classifier Probes,” November 22, 2018. https://arxiv.org/abs/1610.01644.
[2] LeCun, Yann, Corinna Cortes, and Christopher J.C. Burges. “The MNIST Database.” Accessed January 19, 2023. http://yann.lecun.com/exdb/mnist/.
[3] Liu, Rosanne, Joel Lehman, Piero Molino, Felipe Petroski Such, Eric Frank, Alex Sergeev, and Jason Yosinski. “An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution,” December 3, 2018. https://arxiv.org/abs/1807.03247.