Recently I’ve been interested in using autoencoders to model environment dynamics in reinforcement learning tasks. As the agent interacts with the environment an autoencoder could be trained on the observed frames to extract features of the environment which can be used for reasoning and planning. There’s a lot of ideas I want to try out in this area, but the first step is to train a basic autoencoder to reconstruct frames of a simple video game. In this article I’ll discuss my experiments training autoencoders on frames from Montezuma’s Revenge, a game for the Atari 2600 widely used in reinforcement learning research [2]. In particular, I will compare the effectiveness of standard autoencoders to variational autoencoders on this task.
The source code for this article can be found on GitHub.
Background
Autoencoders
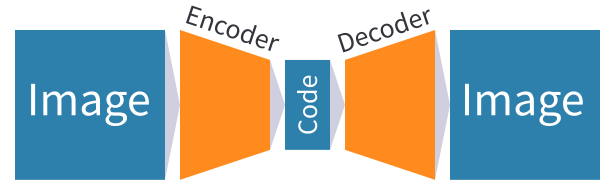
As discussed in my previous article, autoencoders are a type of deep learning model used to learn smaller representations of data (such as images) in an unsupervised manner. An autoencoder consists of two neural networks:
- An encoder, which takes an image as input, and outputs a (much smaller) vector embedding representing the image.
- A decoder, which takes the aforementioned vector embedding as input and outputs the original image that was passed to the encoder to produce that embedding.
The encoder and decoder are trained together by using images from the dataset as both the input data and target outputs. This setup aims to make the encoder learn to output vector embeddings that contain the underlying information necessary for the decoder to reconstruct the input images as accurately as possible. This information is likely to also be useful for other tasks in the same environment, such as planning.
Variational Autoencoders
The basic autoencoders described in the previous section can be very good at extracting useful features from a dataset, however they have some problems that limit their usefulness. One big issue is that ideally we want similar images to have similar embedding vectors, however regular autoencoders do not guarantee that this is the case, and will often jumble together very different images in latent space. Variational autoencoders solve this issue with a small change to the training process: rather than the encoder outputting a single embedding vector for each image, it outputs the mean and variance of a normal distribution over possible embedding vectors for the image [3]. This distribution is then randomly sampled to get the embedding vector that will be fed to the decoder. This means that nearby vectors in latent space must represent similar images, otherwise this added noise will change the image too much and degrade the accuracy of the decoder significantly.
Kullback–Leibler Loss
The problem with the above modification is that the challenges posed by the added noise can be easily bypassed by just making all the vector embeddings really far away from each other, so that the noise won’t cause different vectors to get mixed up. To stop this from happening, variational autoencoders also adjust the loss function to encourage all the vector embeddings to roughly fit a standard normal distribution. This is done by adding a Kullback-Leibler divergence term to the loss [3], which measures how different the embedding distribution is to the standard normal distribution. By simultaneously trying to minimise the reconstruction error and the Kullback-Leibler divergence, a variational autoencoder learns useful vector embeddings of images such that similar images have similar embeddings.
Montezuma’s Revenge

Montezuma’s Revenge is a video game for the Atari 2600 games console which is widely used for testing reinforcement learning algorithms [2]. The game is a side-on platformer consisting of multiple rooms that the player must explore to find useful items and treasure, while avoiding enemies and traps. Compared to other Atari games it is infamously difficult for reinforcement learning agents, due to the sparsity of rewards in the game. I find the game interesting to study because it mixes short term action selection, such as the timing of a jump, with long term planning, such as how to plot a route to a key via various moving obstacles.
The autoencoders discussed in this article were trained on a dataset of frames from the game. The dataset is a subset of Google Research’s DQN Replay Dataset,[1] which was generated by getting one of their reinforcement learning agents to play the game for a long period of time. I filtered the dataset to only include frames where the agent has yet to receive any reward, meaning the dataset only contains frames from the first room of the game, which simplifies the problem.
Experiments
The aim of this project is to try out a few different ways of training autoencoders, to see which one works best on frames from the first room of Montezuma’s Revenge. In this section I’ll be presenting the results from three different autoencoders:
A standard autoencoder, in which the encoder outputs a single vector embedding per image and is trained with the reconstruction loss only.
A variational autoencoder, in which the encoder outputs the mean and variance of an embedding distribution which is sampled to generate the input for the decoder, also trained with reconstruction loss only.
A variational autoencoder as above that also uses a Kullback-Leibler loss term in addition to the reconstruction loss.
I also tried using the CoordConv autoencoders discussed in my previous article for this problem, but the locality of the decoder meant they were unable to reconstruct the background level geometry, and other variations of the CoordConv model that I tried did not perform well compared to the methods shown here.
Results

All of the autoencoders tested seem to produce reasonably high quality reconstructions for most frames, however they all seem to struggle when the player is in a part of the screen less represented in the training data, such as the upper left corner. This suggests poor generalisation to player positions outside the training data, which could perhaps be mitigated with techniques like CoordConv, or using a validation dataset to ensure the model is not overfitting to the training data. The variational autoencoder without a Kullback Leibler loss term yielded the lowest reconstruction error on average; adding the extra loss term seems to make accuracy degrade, although it is possible that choosing a different weighting for the loss terms might improve this.

Interactive Play
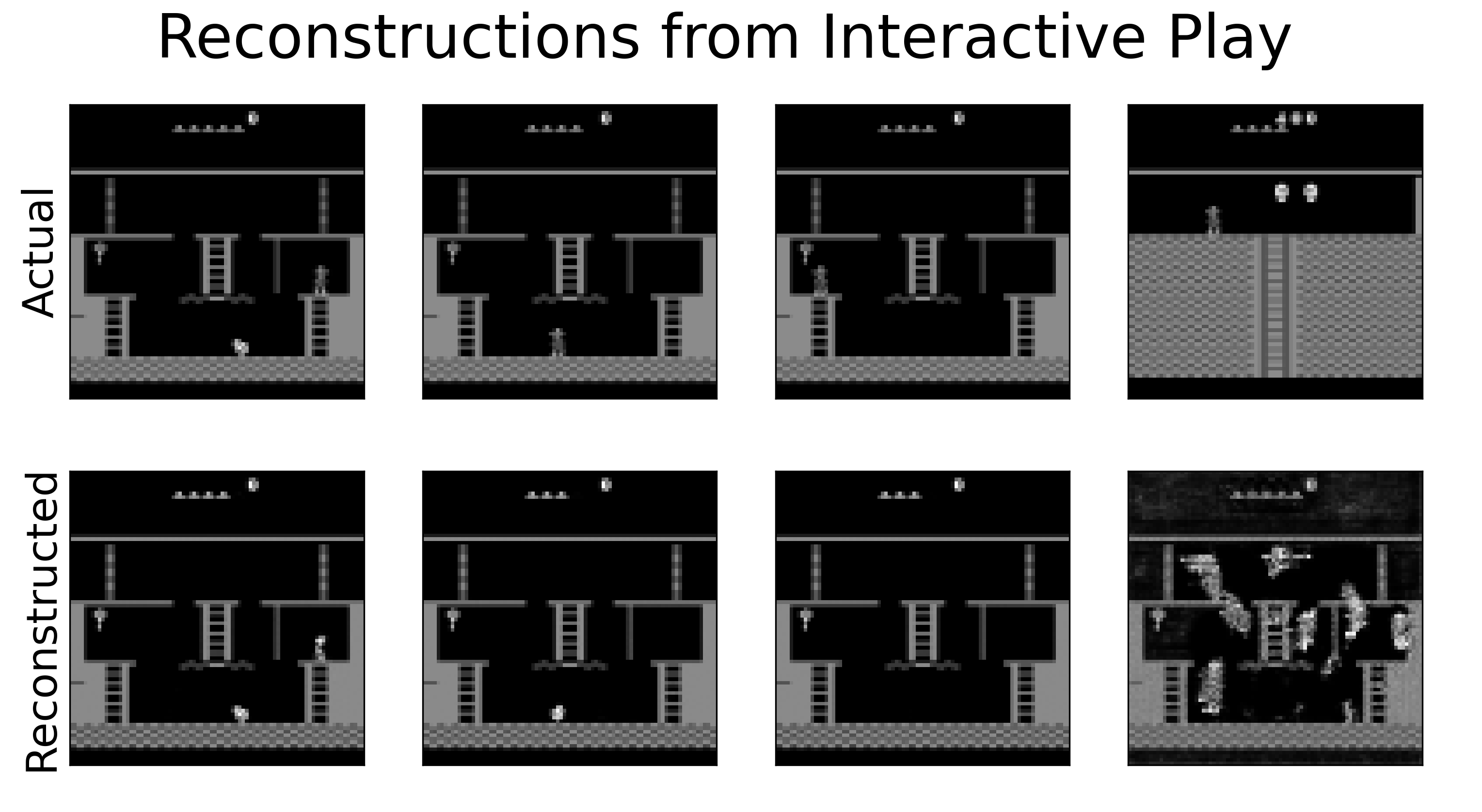
As well as evaluating the accuracy of the autoencoders on a test dataset as usual, I thought it would be fun to try playing the game myself with reconstructions from the variational autoencoder shown alongside the actual video output. We can see that the autoencoder performs fairly well in the first room, although it easily confuses the player with the skull when it is at the bottom of the screen. It seems unable to represent the player being near the key, presumably because that situation did not appear much in the training data. Unsurprisingly the autoencoder performs especially badly in other game rooms that it has never seen before, hallucinating lots of ghosts on the screen!
Conclusion
The results of these experiments seem to suggest that getting the encoder to output normal distributions over embeddings improves reconstruction accuracy compared to a standard autoencoder, but adding a Kullback-Leibler loss term degrades accuracy. More experiments could be done to see if changing hyperparameters affects this, but the autoencoders trained here should be a good starting point for my future projects using autoencoders for reinforcement learning.
The source code for this article can be found on GitHub.
References
[1] Agarwal, Rishabh, Dale Schuurmans, and Mohammad Norouzi. “DQN Replay Dataset.” Google Research, 2020. https://research.google/resources/datasets/dqn-replay/.
[2] Bellemare, M. G., Y. Naddaf, J. Veness, and M. Bowling. “The Arcade Learning Environment: An Evaluation Platform for General Agents.” Journal of Artificial Intelligence Research 47 (2013): 253–79. https://doi.org/10.1613/jair.3912.
[3] Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013). https://arxiv.org/abs/1312.6114